The Ground is Lava CS 175 - Project in AI (in Minecraft)
Video
Project Summary
Over the duration of this project course, we created an agent that learns to solve arbitrary mazes. Our representation of a maze in the Malmo environment consists of dirt blocks over a floor of lava. The agent’s objective is to navigate over the dirt blocks to a single lapis block the “goal block” which denotes the end of the maze. These mazes were generated randomly using our implementation of the randomized Prim-Jarnik minimum spanning tree algorithm which typically produces mazes that are difficult to solve.
The Markov Decision Process (MDP) we used to model the environment is comparable to a gridworld. Each block of the maze is represented as a coordinate position (a tuple of integers which are in the form (int+0.5, int+0.5) in the actual code) on a grid. The size of the grid is nxn and can be varied by the user to create mazes of different sizes for the agent to solve. Each state is a position on the grid and an agent can transition to a future state by moving one block at a time in either the north, south, east or west direction. The agent’s actions are restricted to a move in any of these four directions and of the form “move [direction] 1” (i.e. strings, which are discrete Malmo movement commands). The action set for a state contains only the actions that are executable from that state (coordinate position). An episode in the MDP ends when the agent reaches the goal block or dies by entering lava.
The agent’s percepts are highly limited in that it only knows its current position (the coordinate position of the grid). Consequently, the agent has no field of vision and does not know if there is a goal state. With this restriction of available information in our problem definition, our agent must learn how to solve the maze by exploring the unknown environment and storing associated reward values for the sequences of actions it takes. The closer the agent gets to the goal the higher the reward value. Thus, our agent iterates through multiple episodes on the same maze eventually learning a sequence of actions that will obtain the maximum reward.
We first implemented an on-policy learning algorithm called the State-Action-Reward-State-Action (Sarsa) algorithm to learn the MDP policy. This was completed and analyzed in our status report (status.md). To build upon our approach we decided to implement another on-policy learning algorithm called Sarsa(lambda), which adds “eligibility traces” to the Sarsa algorithm. This allowed us to strengthen our evaluation of our Sarsa algorithm by comparing the results we obtained from Sarsa with the data we collected from the Sarsa(lambda) algorithm.
Approaches
We will provide a brief recap of how the Sarsa algorithm is able to solve mazes in the Malmo environment. A more detailed description can be seen in our “Approach” section of our status report. We continue with an explanation of the Sarsa(lambda) algorithm, which was implemented after the status report.
Our problem definition requires our agent to learn in a gridworld where it only knows its current position and can take actions that will allow it to move a single block north, south, east, or west. Our base algorithm is the “Sarsa algorithm” (which we will henceforth call “plain Sarsa” to distinguish it from the “Sarsa(lambda)” algorithm discussed later), which the agent uses to learn the optimal MDP policy, which is simply a sequence of actions that maximize the summation of future rewards. At the start of the algorithm, the agent’s initial state is block (0,0) and the Q table contains the initial state-action entry with Q value 0. For each state-action pair the Sarsa algorithm updates the Q values (adding new states to the Q table as they are discovered) according to the following update rule:
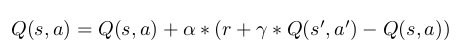
where s’ is the state arrived at by taking action a from s, and a’ is the action chosen from state s’ according to an epsilon greedy policy. As usual, r denotes the reward, alpha functions as learning rate, and gamma functions as the discount factor. Our epsilon-greedy policy randomly chooses an action from state s with probability 1/N(s) where N(s) is the number of times we’ve visited state s, and otherwise chooses the locally optimal action for the given state. We also discussed the crucial “Manhattan distance” heuristic we endowed the agent with, in which we discount states by their distance from the start state, in order to encourage the agent to move in the direction of the goal.
Everything described thus far is implemented in the file “sarsa1.py”, with miniscule changes since the status report.
The mazes are generated using a randomized Prim-Jarnik minimum spanning tree algorithm, as described here: https://en.wikipedia.org/wiki/Maze_generation_algorithm#Randomized_Prim.27s_algorithm. This is implemented in maze_gen2.py (and subsequently called in the malmo files).
The Sarsa(lambda) algorithm differs from the Sarsa algorithm by requiring the agent to store a Q table and an E table which contains information about “eligibility traces”. The eligibilty traces keep track of the states that have been recently visited and are a measure how “eligible” a state is for an update. The entries of the E table are a state-action pair that have been carried out by the agent and an associated e value. Upon using a state-action pair s’, a’, we increment its E table entry:
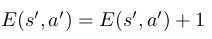
And subsequently update the E table entries for every state s,a (including s=s’ and a=a’) according to the following equation:
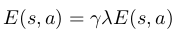
The eligibility trace for a state decays at a rate of gamma*lambda. Gamma is the discount factor previously described in the Sarsa algorithm and lambda is the decay parameter, a value between 0 and 1 that controls how much “credit” is given to states in the past. The E table entry for s and a (The “eligibility trace” for s/a) measures “how far away” a given previously used state-action pair is from a current state s’. With this, we can take the reward for s’ and not only update Q table for the previous state, but every visited state s up to that point with the following equation:
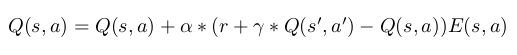
which is the same update equation for plain Sarsa except that the error is multiplied by the eligibility trace for s/a. Thanks to the manner in which eligibility traces are updated, we change the Q value for s/a by an amount inversely proportional to “how far back in the past” it is (which is what our E table measures). In other words, we “attribute” the reward gained at the current state to s based on how far back in the past it was. A state-action pair is “more eligible” for the reward gained at the current state if it was more closely related to it. Note: The eligibility trace is higher not only if the state was more recently visited, but more frequently visited. Our agent does not repeat states that often (though sometimes it does) so we are more focused on the “time”-based factor of it.
This is implemented in the file “sarsalambda1.py” All in all, this required only a few additional lines of code to the original Sarsa algorithm (In fact, we could have consolidated plain Sarsa and Sarsa(lambda) into one file). However, it made a huge difference in the agent’s performance as discussed in the Evaluation section.
Evaluation
In order to further our evaluation from the status report, we gathered data on our Sarsa(lambda) algorithm and to compare to the results obtained from running our Sarsa algorithm. Our primary evaluation measure was examining the performance of each agent. We defined “convergence” as reaching the goal state 3 times in a row and recorded the number of episodes the agent takes to converge. We tested this on both algorithms for a varity of maze sizes and our results are displayed in the following graph:
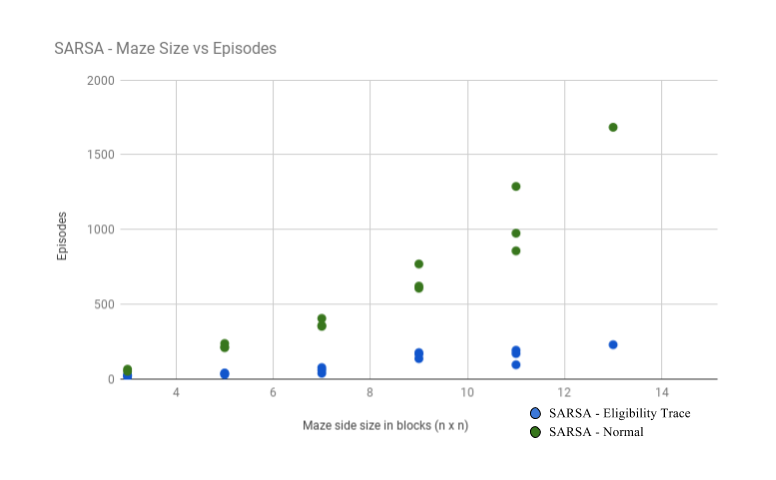
Sarsa(lambda) appears to drastically outperform plain Sarsa on our MDP. Our intuition leads us to believe that the reasoning for this outcome is that eligibility traces allow the reward for a given state to propagate backwards. Let us examine a simple example that demonstrates this by considering the environment pictured below, where the red box is the start state lava, the white boxes signify the dirt blocks of the maze, and the green block is the goal state:
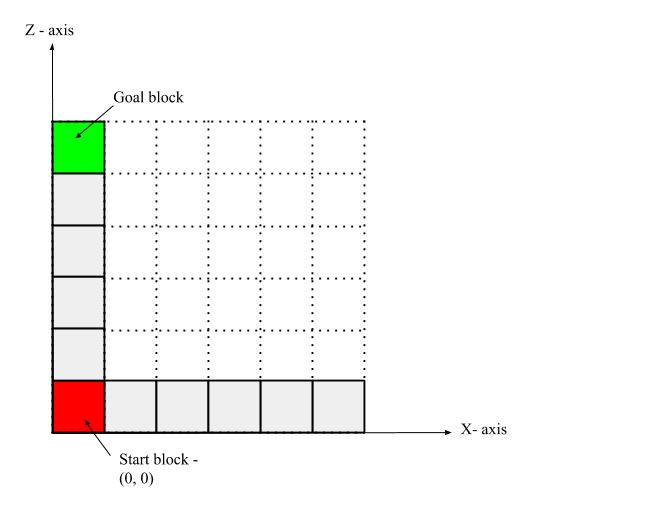
Obviously, the better decision from the start state is to move north to the goal (marked in green) than moving east to a dead-end (lava). Suppose the agent tends to move all the way east and fall into the lava (moving east from the start state, falling into (6,0) is actually the best option). In Sarsa(lambda), the negative reward obtained from doing so immediately propogates back to the state-action pair (0,0)-east, as a consequence of the update rule. Hence, the agent quickly sees that (0,0)-east (and likewise, (1,0)-east, (2,0)-east, etc.) is a bad idea and will prefer to try a different action instead, in this case north. On the other hand, in plain Sarsa, only the state-action pair (5,0)-east immediately gets the negative reward. For the negative reward to propogate back to (0,0)-east the agent has to revisit (5,0)-east, which updates the value for (4,0)-east, restart, then revisit (4,0)-east, which updates the value for (3,0)-east, then revisit (3,0)-east, etc. Thus, it can take up to 5 extra episodes for (0,0)-east to be properly updated in Sarsa, while for Sarsa(lambda) it only takes 1. Similarly, a positive reward obtained at the goal state propogates back faster in Sarsa(lambda) than it does for Sarsa. Now consider this for not just the start state, but every position in the maze, and it becomes clear why Sarsa(lambda) requires fewer episodes to converge.
We noted in our status report that we would like to test our agent(s) on larger maze sizes. As it turns out, this is exactly where we started to run into problems. Specifically for maze sizes 13x13 and beyond, the agents (particularly Sarsa(lambda)) would get stuck in a “local maxima” where the agent would start to go back and forth between two states repeatedly until the episode ends. It would repeat this behavior episode after episode and thus fail to converge in a reasonable amount of time. We are quite certain that this is due to the discounting factor gamma. The agent finds that if it goes back and forth endlessly between two states, its discounted reward for those states would be gamma^n*r where n is the number of actions it can take within a given episode (which is quite large). Since gamma is between 0 and 1, this pushes the discounted reward for those states towards 0, and since every state other than the goal state yields negative reward, this is “good” from the agent’s point of view. Thus explaining why it would get stuck in pockets where it simply alternates between states. We confirmed this further by increasing gamma from 0.9 to 0.99999. After only increasing gamma, the agent no longer exhibited the back-and-forth behavior and–as far as we had tested–managed to converge on larger maze sizes. With this change in gamma, the agents are now technically “different” from the agents we used to gather the data in the graph. Thus, the data is not comparable. We were only able to collect data on larger maze sizes for these agents with the higher gamma in an attempt to test our theory of convergence. Since we were not able to recollect data on all maze sizes, we were not able to incorporate this data and hence, we believe qualitatively that this increase in gamma would allow our agent to scale to larger maze sizes to a reasonable extent (The other necessary change would be to scale up the rewards by a certain factor, which is simple enough).
References
Introduction to Reinforcement Learning, 3rd Edition. Richard S. Sutton and Andrew G. Barto
https://en.wikipedia.org/wiki/Maze_generation_algorithm#Randomized_Prim.27s_algorithm